背景
近年来随着边缘计算和物联网的兴起与发展,许多移动终端(比如手机)成为了深度学习应用的承载平台,甚至出现了各式各样专用的神经网络计算芯片。由于这些设备往往对计算资源和能耗有较大限制,因此在高性能服务器上训练得到的神经网络模型需要进行裁剪以缩小内存占用、提升计算速度后,才能较好地在这些平台上运行。
一种最直观的裁剪方式就是用更少位数的数值类型来存储网络参数,比如常见的做法是将 32 位浮点数模型转换成 8 位整数模型,模型大小减少为 1/4,而运行在特定的设备上其计算速度也能提升为 2~4 倍,这种模型转换方式叫做量化(Quantization)。
量化的目的是为了追求极致的推理计算速度,为此舍弃了数值表示的精度,直觉上会带来较大的模型掉点,但是在使用一系列精细的量化处理之后,其在推理时的掉点可以变得微乎其微,并能支持正常的部署应用。
原理
实现量化的算法多种多样,一般按照代价从低到高可以分为以下四种:
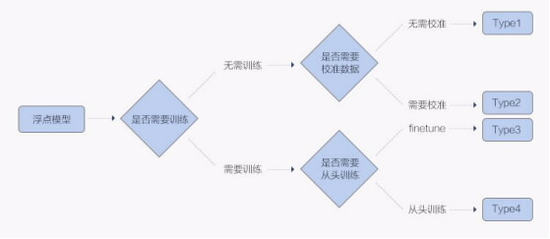
Type1 和 Type2 由于是在模型浮点模型训练之后介入,无需大量训练数据,故而转换代价更低,被称为后量化(Post Quantization),区别在于是否需要小批量数据来校准(Calibration);
Type3 和 Type4 则需要在浮点模型训练时就插入一些假量化(FakeQuantize)算子,模拟量化过程中数值截断后精度降低的情形,故而称为量化感知训练(Quantization Aware Training, QAT)。
以常用的 Type3 为例,一个完整的量化流程分为三阶段:(1)以一个训练完毕的浮点模型(称为 Float 模型)为起点;(2)包含假量化算子的用浮点操作来模拟量化过程的新模型(Quantized-Float 模型或 QFloat 模型);(3)可以直接在终端设备上运行的模型(Quantized 模型,简称 Q 模型)。
由于三者的精度一般是 Float > QFloat > Q ,故量化算法也就分为两步:
· 拉近 QFloat 和 Q:这样训练阶段的精度可以作为最终 Q 精度的代理指标,这一阶段偏工程;
· 拔高 QFloat 逼近 Float:这样就可以将量化模型性能尽可能恢复到 Float 的精度,这一阶段偏算法。
第一步在MegEngine框架的“训练推理一体化”特性下得到了保证,而第二步则取决于不同的量化算法。
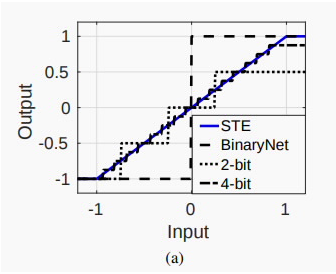
尽管不同量化算法可能在假量化的具体实现上有所区别,但是一般都会有一个“截断”的操作,即把数值范围较大的浮点数转换成数值范围较小的整数类型,比如下图,输入一个[-1, 1)范围的浮点数,如果转换为 4 位整型,则最多只能表示 2^4 个值,所以需要将输入的范围划分为16段,每段对应一个固定的输出值,这样就形成了一个类似分段函数的图像,计算公式为:
[公式]
另外,由于分段函数在分段点没有梯度,所以为了使假量化操作不影响梯度回传,就需要模拟一个梯度,最简单的方法就是用y=x来模拟这一分段函数,事实证明这么做也是有效的,这种经典的操作被称为“Straight-Through-Estimator”(STE)。
工程
量化部分作为模型推理部署的重要步骤,是业界在大规模工业应用当中极为关注的部分,它在 MegEngine 的底层优化中占了很大比重。在目前开源的版本里,针对三大平台(X86、CUDA、ARM),MegEngine都有非常详细的支持,尤其是ARM平台。
一般在通用计算平台上,浮点计算是最常用的计算方式,所以大部分指令也是针对浮点计算的,这使得量化模型所需的定点计算性能往往并不理想,这就需要针对各个平台优化其定点计算的性能。
ARM 平台
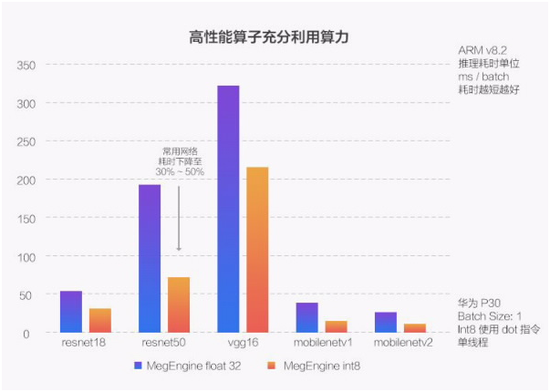
ARM平台一般是指手机移动端,其系统架构和底层指令都不同于我们熟知的电脑CPU,而随着架构的变迁,不同架构之间的指令也存在不兼容的问题。为此,MegEngine针对ARM v8.2前后版本分别实现了不同的优化:
· ARM v8.2 主要的特性是提供了新的引入了新的 fp16 运算和 int8 dot 指令,MegEngine基于此进行一系列细节优化(细节:四个int8放到一个128寄存器的32分块里一起算),最终实现了比浮点版本快2~3倍的速度提升
· 而对于v8.2之前的ARM处理器,MegEngine则通过对Conv使用nchw44的layout和细粒度优化,并创新性地使用了int8(而非传统的int6)下的winograd算法来加速Conv计算,最使实现能够和浮点运算媲美的速度。
CUDA 平台
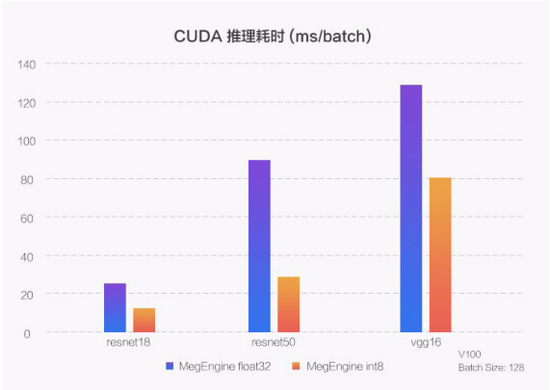
CUDA 平台是指 NVIDIA 旗下 GPU 平台,由于提供 CUDNN 和 Toolkit 系列接口以及 TensorRT 专用推理库,大部分算子可以使用官方优化,而 MegEngine 则在此基础上进行了更多细节的优化,比如如何更好地利用 GPU 的TensorCore 进行加速,不同型号之间一些差异的处理等,最终效果根据不同模型也有非常明显的推理加速。
X86 平台
X86 平台是指 Intel CPU 平台,近年来随着深度学习的发展,其也慢慢提供了针对定点运算更多的支持。
· 在新一代至强(Xeon)处理器上,通过使用 VNNI(Vector Neural Network Instructions)指令,MegEngine 将 CPU 的 int8 推理性能优化到了浮点性能的 2~3 倍。
· 而对于不支持 VNNI 指令的 CPU,一般只提供最低 int16 的数值类型支持,则通过使用 AVX2(Advanced Vector Extensions)这一向量格式,实现了 int8 推理性能与浮点性能持平。
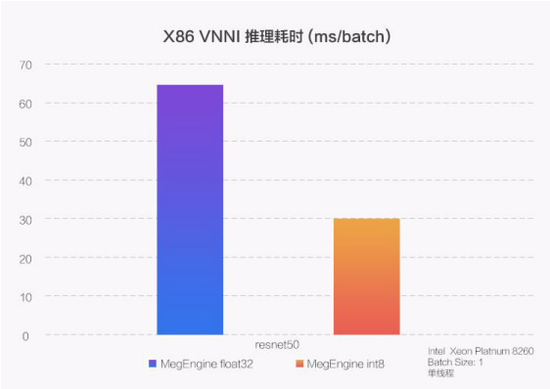
以上是对各个平台推理加速效果的整体介绍,更多更细节的介绍可以期待之后的系列文章。
使用
除了底层实现上的加速与优化,在 Python 侧训练部分,MegEngine对接口也有很多细节设计,使得整体代码逻辑清晰简洁。
我们在 Module 中额外引入了两个基类:QATModule、QuantizedModule 。分别代表上文提及的带假量化算子的 QFloat 模型与 Q 模型,并提供普通 Module → QATModule → QuantizedModule 三阶段的转换接口。各个版本的算子是一一对应的,且通过合理的类继承免除了大量算子实现中的冗余代码,清晰简洁。
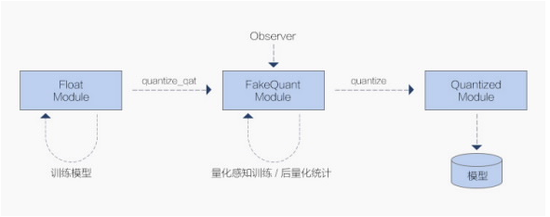
如上图,用户首先在普通 Module 上进行正常的模型训练工作。训练结束后可以转换至 QFloat 模型上,通过配置不同的 Observer 和假量化算子来选择不同的量化参数 scale 获取方式,从而选择进行 QAT 或 Calibration 后量化。之后可以再转换至 Q 模型上,通过 trace.dump 接口就可以直接导出进行部署。
针对推理优化中常用的算子融合,MegEngine 提供了一系列已 fuse 好的 Module,其对应的 QuantizedModule 版本都会直接调用底层实现好的融合算子(比如 conv_bias)。
这样实现的缺点在于用户在使用时需要修改原先的网络结构,使用 fuse 好的 Module 搭建网络,而好处则是用户能更直接地控制网络如何转换,比如同时存在需要 fuse 和不需要 fuse 的 Conv 算子,相比提供一个冗长的白名单,我们更倾向于在网络结构中显式地控制,而一些默认会进行转换的算子,也可以通过 disable_quantize 方法来控制其不进行转换。
另外我们还明确了假量化算子(FakeQuantize)和Observer的职责,前者将主要负责对输入进行截断处理的计算部分,而后者则只会记录输入的值,不会改变输出,符合 Observer 的语义。
在配置使用上,用户需要显式指定针对 weight、activation 分别使用哪种 Observer 和 FakeQuantize,比如:

这样的好处在于,用户可以控制每一处量化过程的细节,可以分别采用不同量化算子和数值类型。
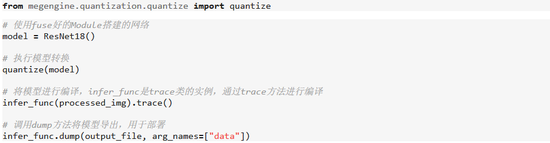
下文简单说明一下在 MegEngine 中转换一个 ResNet 网络的全流程代码:
Float → QFloat:

QFloat → Q 并导出用于部署:
本文简单介绍了神经网络模型实际应用在移动平台必不可少的一步——量化,以及天元(MegEngine )在量化上做的一些工作:包括底层针对不同平台的一些优化效果,在用户接口使用上的一些设计理念。
天元(MegEngine)相信,通过简洁清晰的接口设计与极致的性能优化,“深度学习,简单开发”将不仅惠及旷视自身,也能便利所有的研究者,开发者。
参考文献
[1] Moons, B., Goetschalckx, K., Van Berckelaer, N., & Verhelst, M. (2017, October). Minimum energy quantized neural networks. In 2017 51st Asilomar Conference on Signals, Systems, and Computers (pp. 1921-1925). IEEE.
[2] Jacob, B., Kligys, S., Chen, B., Zhu, M., Tang, M., Howard, A., ... & Kalenichenko, D. (2018). Quantization and training of neural networks for efficient integer-arithmetic-only inference. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (pp. 2704-2713).
[3] Zhou, A., Yao, A., Guo, Y., Xu, L., & Chen, Y. (2017). Incremental network quantization: Towards lossless cnns with low-precision weights. arXiv preprint arXiv:1702.03044.
[4] Li, F., Zhang, B., & Liu, B. (2016). Ternary weight networks. arXiv preprint arXiv:1605.04711.
[5] Rastegari, M., Ordonez, V., Redmon, J., & Farhadi, A. (2016, October). Xnor-net: Imagenet classification using binary convolutional neural networks. In European conference on computer vision (pp. 525-542). Springer, Cham.
版权及免责声明:凡本网所属版权作品,转载时须获得授权并注明来源“融道中国”,违者本网将保留追究其相关法律责任的权力。凡转载文章,不代表本网观点和立场。
延伸阅读

 马斯克V.S薛其坤:立足当下 对人类未来展开无限想象
马斯克V.S薛其坤:立足当下 对人类未来展开无限想象
 众安在线扭亏为盈:2020年净利5.5亿 数字生活生态驱动增长
众安在线扭亏为盈:2020年净利5.5亿 数字生活生态驱动增长
版权所有:融道中国